Perhaps of interest to some who live in counties that have an upcoming
election, I’ve been exploring the use of XSLT 3.0 Streaming for the
processing of very large data sets produced by voting equipment. These data
sets are commonly referred to as “Cast Vote Records” and describe
selections on ballots, the number of votes those selections represent,
their countability (among other things). NIST has released a Common Data
Format specification <https://github.com/usnistgov/CastVoteRecords> for
such records that can use XML.
There has been some concern that the XML representation of this information
is simply too large to process effectively. To test that premise, I
developed a test deck generator and tabulator
<https://github.com/HiltonRoscoe/CDFPrototype/blob/feature/streaming-cvr/CVR/STREAMING.md>
capable of naïvely tabulating the contests. Both are written in XSLT 3.0. I
generated test decks of various sizes to get a better idea of the
scalability of different processing approaches.
The first approach is to load the entire CVR set in memory and operate on
it. The second approach is to “burst-mode” stream each CVR using XSLT 3.0
Streaming. I ran each transform 25 times for each set and averaged the
results.
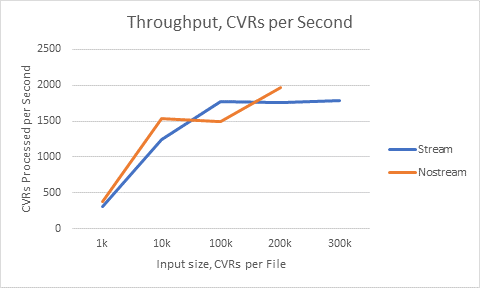
*1k*
*10k*
*100k*
*200k*
*300k*
*Stream*
313/sec
1237/sec
1778/sec
1762/sec
1785/sec
*Nostream*
379/sec
1536/sec
1487/sec
1974/sec
-
*INPUT Size (CVRs)*
10,039
100,005
999870
1,999,911
2,999,951
*INPUT Size (Megabytes)*
~10MB
~100MB
~1000MB
~2000MB
~3000MB
(Throughput for different input sizes)
*Inputs*
*Time*
*1k*
Precinct
00:03
*10k*
Rural Jurisdiction
00:08
*100k*
Small Jurisdiction
00:56
*200k*
Midsize Jurisdiction
01:53
*300k*
Midsize Jurisdiction
02:48
(Example processing times for typical jurisdiction sizes using streaming)
*Analysis*
*Non-streaming*
Each 100k of CVR required 4GB to place in memory. This makes the approach
inherently hardware-bound. I surmise that the lower throughput at lower
input sizes is due to the startup cost of the XSLT processor.
*Streaming*
Streaming processing took around 800MB of memory and stayed stable at or
above 100k CVR input size.
*Conclusion*
Large CVRs datasets can be processed effectively, so long as the approach
chosen can scale.
Test Environment: Windows 10 x64, 32GB RAM, Intel i7-7500U, Saxon-EE 10.2J
, Java 1.8.0_151-1-redhat
John Dziurłaj
Elections Consultant
Hilton Roscoe LLC
Cell: 330-714-8935
@Dziurlaj
--~----------------------------------------------------------------
XSL-List info and archive: http://www.mulberrytech.com/xsl/xsl-list
EasyUnsubscribe: http://lists.mulberrytech.com/unsub/xsl-list/1167547
or by email: xsl-list-unsub(_at_)lists(_dot_)mulberrytech(_dot_)com
--~--